Fase 1 - Raccolta dei dati
Per analizzare una rete sociale bisogna avere (tanti) dati a disposizione. Il primo passo è stato quello di realizzare una pagina web per raccogliere i voti dell'utente.
Successivamente sono stati invitati degli utenti (amici, parenti, compagni di università, utenti di facebook, …) a compilare una lista di 50 film e dare un giudizio da 1 a 5 al film oppure un “non l’ho visto”. Oltre alla lista dei voti, ogni utente si caratterizza in base a:
- sesso
- anno di nascita
- genere di film preferito.
Una volta raggiunti i 200 utenti, è stato sviluppato un algoritmo abbastanza semplice per mettere a confronto i voti. I film spaziano da film di animazione a film dell'horrore, da film del 1980 a quelli del 2016.
Fase 2 - Elaborazione
Codice di confronto tra i due utenti
Per dare un peso alla relazione tra due utenti, si è deciso di analizzare i voti che gli utenti hanno espresso. Più i gusti saranno simili più i due utenti saranno amici, mentre, più i valori saranno discordanti più il valore di amicizia sarà basso.
Si è sviluppato quindi il seguente algoritmo:
L’algoritmo prende in input i voti dei due utenti e restituisce:
- Un valore di “similarità” che varia da 0 a 100
- Quanti voti discordi, simili o completamente opposti gli utenti hanno dato
Ad alto livello possiamo immaginarlo come nella seguente foto:
I valori nel rettangolo sono i valori del primo utente, i valori cerchiati in vari colori sono i confronti con il secondo utente.
Se i 2 voti sono uguali allora gli utenti hanno su quel film la massima similarità e quindi ‘acquistano’ 1 punto, se il giudizio è simile (ad esempio utente A vota 4 e utente B vota 5) ‘acquistano’ 0,8 punti, se è completamente opposto non prendono nessun punto e così via…
Il confronto su tutti i film visti da entrambi gli utenti, fornisce un valore di “amicizia” tra di loro che viene salvato in una tabella di un database SQL (mySql in questo caso).
Il tempo impiegato sarà O(n^2) perché deve fare i confronti per ogni utente con tutti gli altri utenti.
Inoltre, se l’utente A non ha visto un film che invece a B è piaciuto molto (voto 4 o 5), si crea per A una lista di film suggeriti da B. Ovviamente si salvano anche i suggerimenti che A dà a B.
Segue il codice della classe che effettua il confronto tra due utenti:
Per caricare la lista degli utenti e iniziare l'algoritmo di confronto, si prendono solamente quegli utenti che hanno votato almeno 5 film:
SELECT reti_user.userid as id, username as label, anno as Year, genere as Gender, preferito, tag, count(reti_voti.voto) as nvoti
FROM reti_user inner join reti_voti
on reti_user.userid = reti_voti.userid
where reti_voti.voto!=0
group by reti_user.userid
having nvoti>5
Una volta che il programma ha confrontato tra loro tutti gli utenti, si ha una piccola rete sociale: gli utenti sono i nodi mentre il valore di similarità tra i nodi sono i nostri archi.
Nonostante siano state salvate tutte le relazioni tra gli utenti, solo quelle maggiori di una certa soglia risultano importanti. Successivamente, si elaborano ulteriormente i dati con una query sql per prendere solo le ‘amicizie’ più significative.
SELECT idA as Source, idB as Target, similaritScore as Weight, same,discord,disagree,opposite FROM reti_confronti where similaritScore>70;
Non è facile trovare una soglia 'giusta', infatti nell’immagine si nota che, diminuendo anche di poco il valore di similarityScore, si ha una crescita importante di archi.

Il risultato finale di tutta l'elaborazione è la tabella con gli archi della nostra rete sociale:
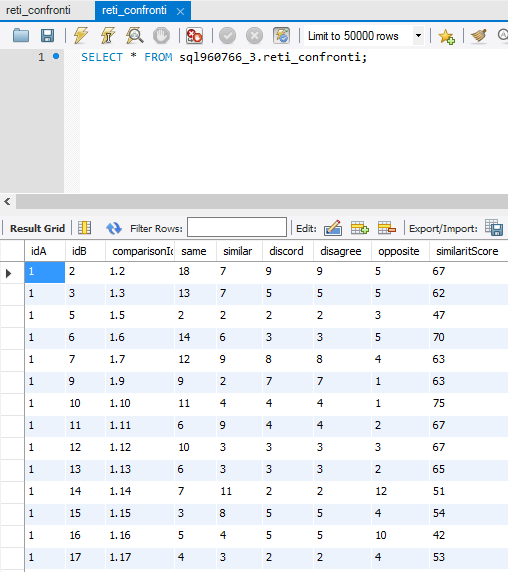
Il passo successivo consiste nel cercare di interpretare questi dati.
Fase 3 - Visualizzazione
Per visualizzare la rete si utilizza Gephi che è un software open source per l'analisi e la visualizzazione delle reti sociali, scritto in Java e basato sulla piattaforma NetBeans.
Inizialmente sviluppato dagli studenti di 'The University of Technology of Compiègne in Francia.
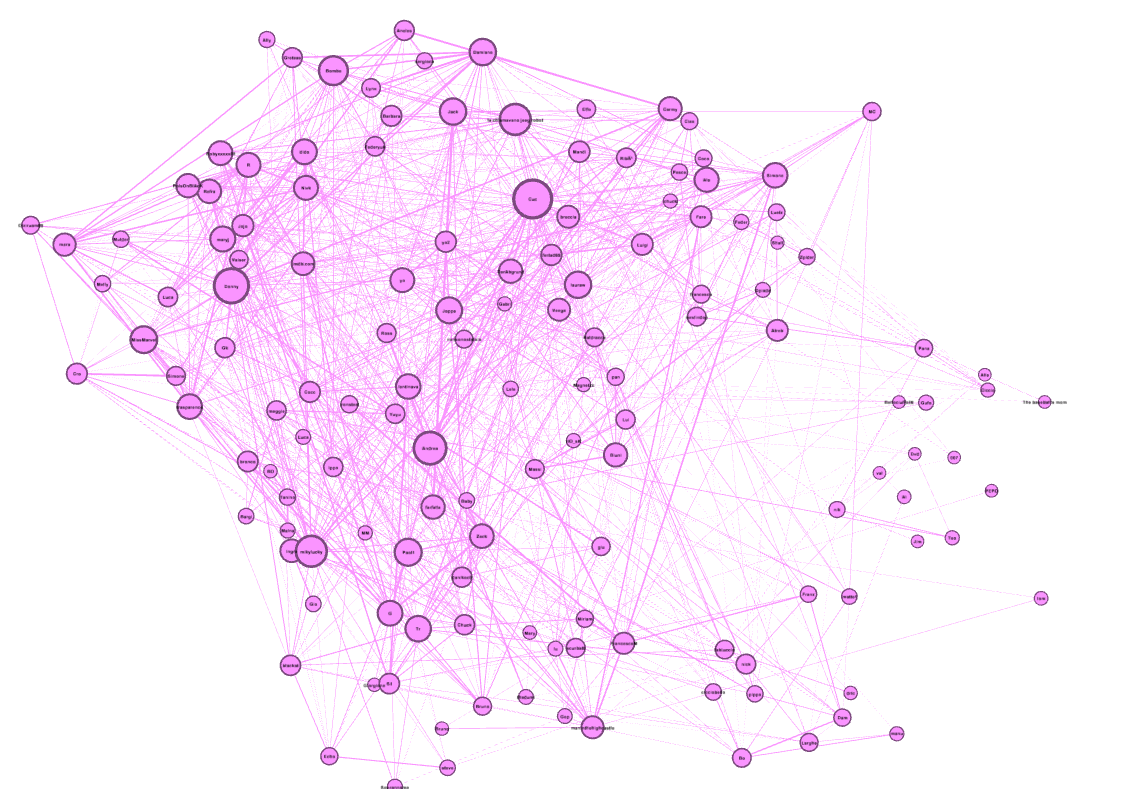
Nella fase iniziale, si importa la rete e si dà un peso ai nodi (in base alla quantità di link che loro hanno). Anche se appare chiaro che alcuni nodi sono più importanti di altri, non si riesce a capire molto di più.
Finita la fase di acquisizione dei dati da parte di Gephy, si fa andare andare l'algoritmo di
weighted degree.
Esso, grazie al numero di archi pesati, determina la grandezza di ogni nodo (effettua la somma pesata degli archi entranti).
Grazie all’opzione ‘node size’, si è quindi data la grandezza del nodo in base al valore appena calcolato con weighted degree. Infine si è fatto andare il filtro modularity che separa in regioni la rete. Colorati i nodi in base alla regione, il risultato è:
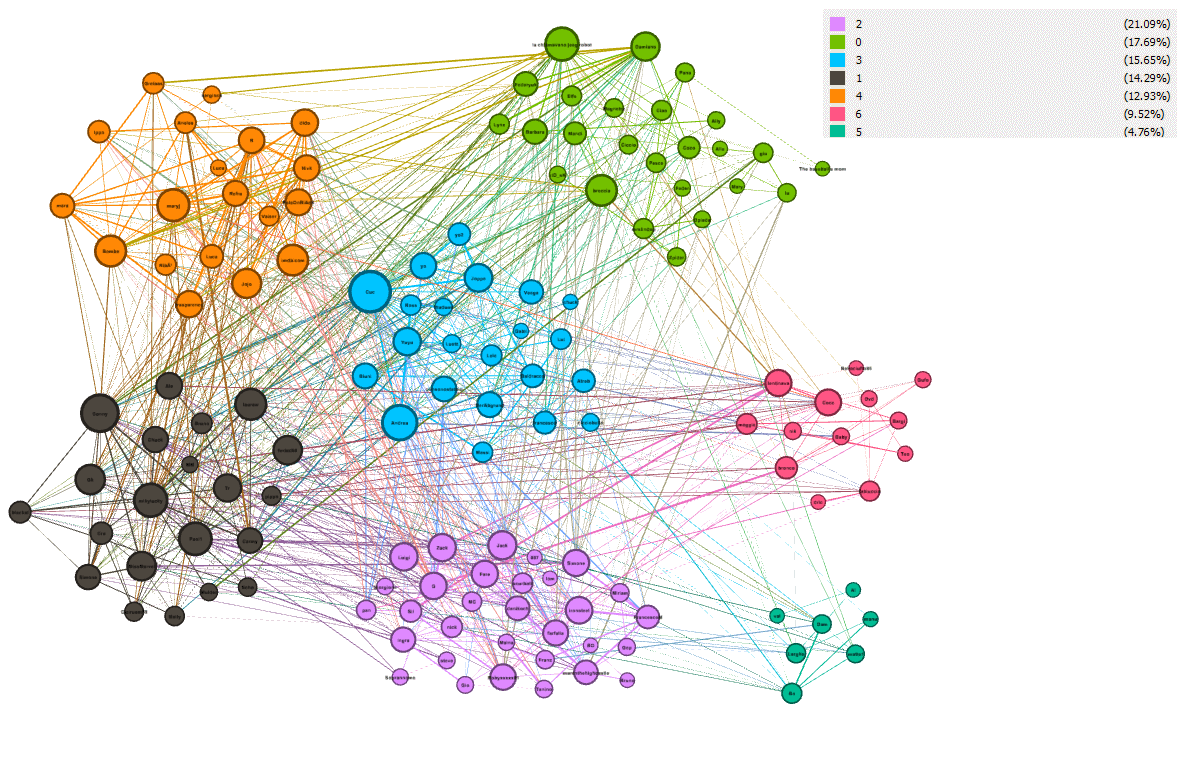
Una prova che il filtro abbia funzionato, è data dal fatto che si è inserito un finto utente “imdb.com” (che ha votato secondo la media del famoso sito di film) [IMDb, the world's most popular and authoritative source for movie, TV and celebrity content]. Effettivamente il nodo “imdb” nella rete ha un peso elevato, è un nodo centrale per la sua regione e questo è verosimile.
Caratteristiche della rete
Per analizzare la rete, Gephi mette a disposizione molte statistiche:
Network diameter
Diameter: 6
Radius: 4
Average Path length: 2.3
Quindi la rete è molto fitta, bastano 2 o 3 passi per raggiungere qualsiasi altro nodo.
Degree Report
Average Degree: 14.748
Ovvero ogni nodo ha in media 14 collegamenti con gli altri nodi. Successivamente è stato ristretto il vincolo di amicizia da 70 a 75% e si è scesi a 7 archi per nodo che però non hanno cambiato drasticamente la rete.
Altre caratterische dei nodi che si possono visualizzare nella rete sono:
Genere
Il campione, come si vede nell'immagine, è rappresentato con il 73% da maschi.
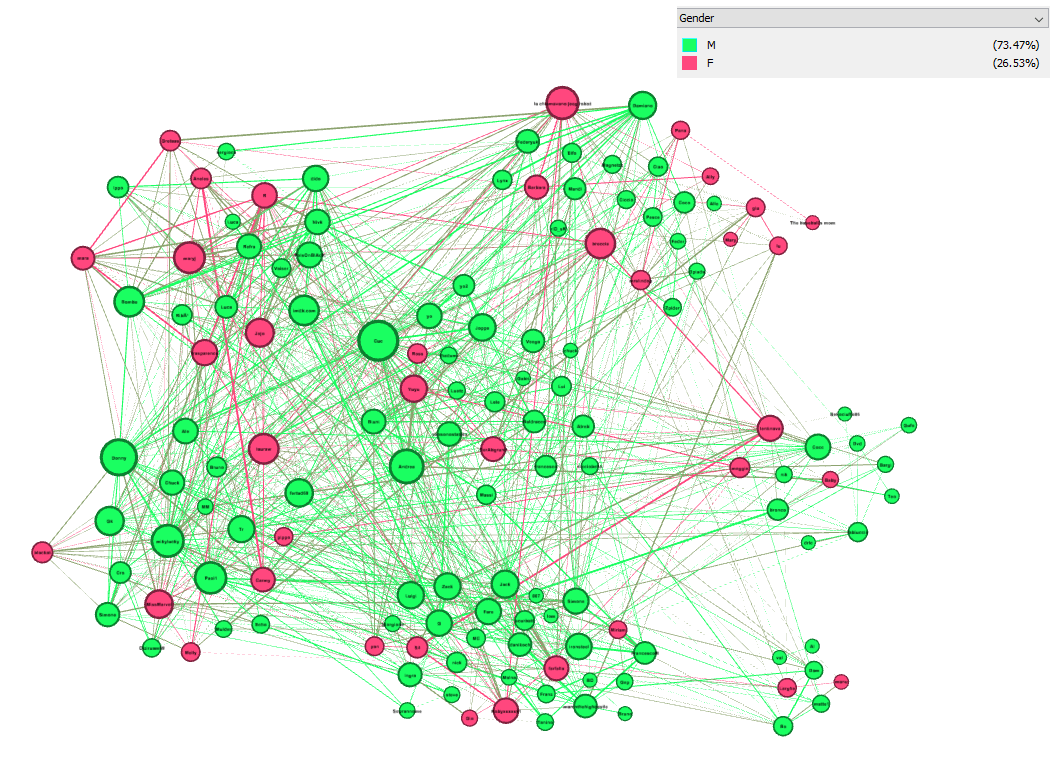
In Gephi quando si seleziona un nodo con il mouse, tutti i nodi suoi amici vengono evidenziati. In questa immagine vediamo in particolare un nodo femmina. Esso possiede molti archi verso altri nodi femmina e questo ci fa venire in mente la caratteristica dell'omofilia.
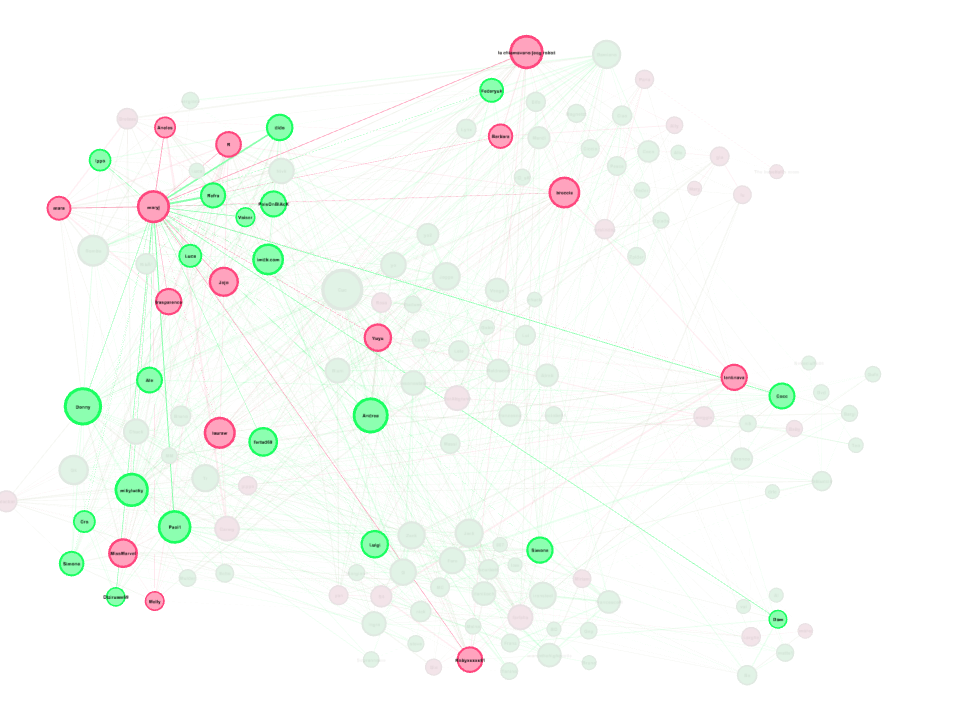
Calcolo omofilia
In sociologia Omofilia (vale a dire, "l'amore del simile/dell'uguale") è la tendenza degli individui di associarsi e di creare legami
con altri considerati simili per alcune peculiari caratteristiche.
La presenza di omofilia è stata descritta in una vasta gamma di studi i quali hanno osservato l'omofilia
in vari contesti e modalità e stabilito una connessione di somiglianza
in differenti ambiti tra cui l'età, l'identità di genere, la classe sociale e il ruolo organizzativo.
Gli individui nelle relazioni omofiliche condividono caratteristiche comuni (credenze, valori, educazione, etc.)
che rendono la comunicazione e la relazione di formazione più facile.
Omofilia porta spesso a omogamia-matrimonio tra persone con caratteristiche simili. [da Wikipidia]
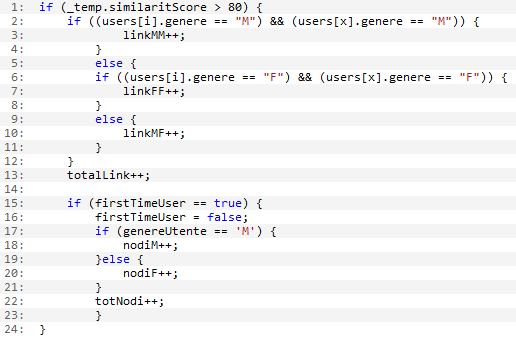
Per analizzare se in una rete sociale è presente omofilia, si sono aggiunti dei contatori nel codice per calcolare:
- Il numero di nodi
- Il numero di nodi 'genere maschio'
- Il numero di archi
- Il numero di archi tra nodi maschi e nodi femmina
In base al tasso di similarità minimo tra due nodi si è quindi ottenuto:
60% -> Ci sono totalLink= 3188, linkFF=243, linkMF=1198 e linkMM=1747. Ci sono nodi totali =141, nodi Femmina=37 e nodi Maschi=104
70% -> Ci sono totalLink= 1083, linkFF=95, linkMF=436 e linkMM=552. Ci sono nodi totali =129, nodi Femmina=35 e nodi Maschi=94
80% -> Ci sono: totalLink= 190, linkFF=22, linkMF=79 e linkMM=89. Ci sono nodi totali =81, nodi Femmina=26 e nodi Maschi=55
Se si applica la formula 2*p*q > (link cross genere / numero totale dei link) e questa risulta essere vera, allora si ha un caso di omofilia.
Variando il valore di similarità, si ottengono diversi risultati:
- similarità maggiore del 60%
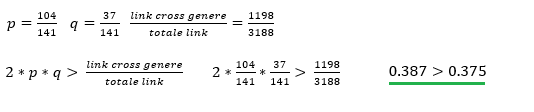
- similarità maggiore del 70%

- similarità maggiore del 80%

In questa rete per genere risulta che:
- vi è pochissima omofilia se si tiene il limite similarità tra nodi maggiore del 60%
- non vi è omofilia se il limite di similarità viene spostato sopra il 70%
Si può concludere che in questa rete sociale, anche se appariva la possibilità di omofilia per sesso, questa non è presente.
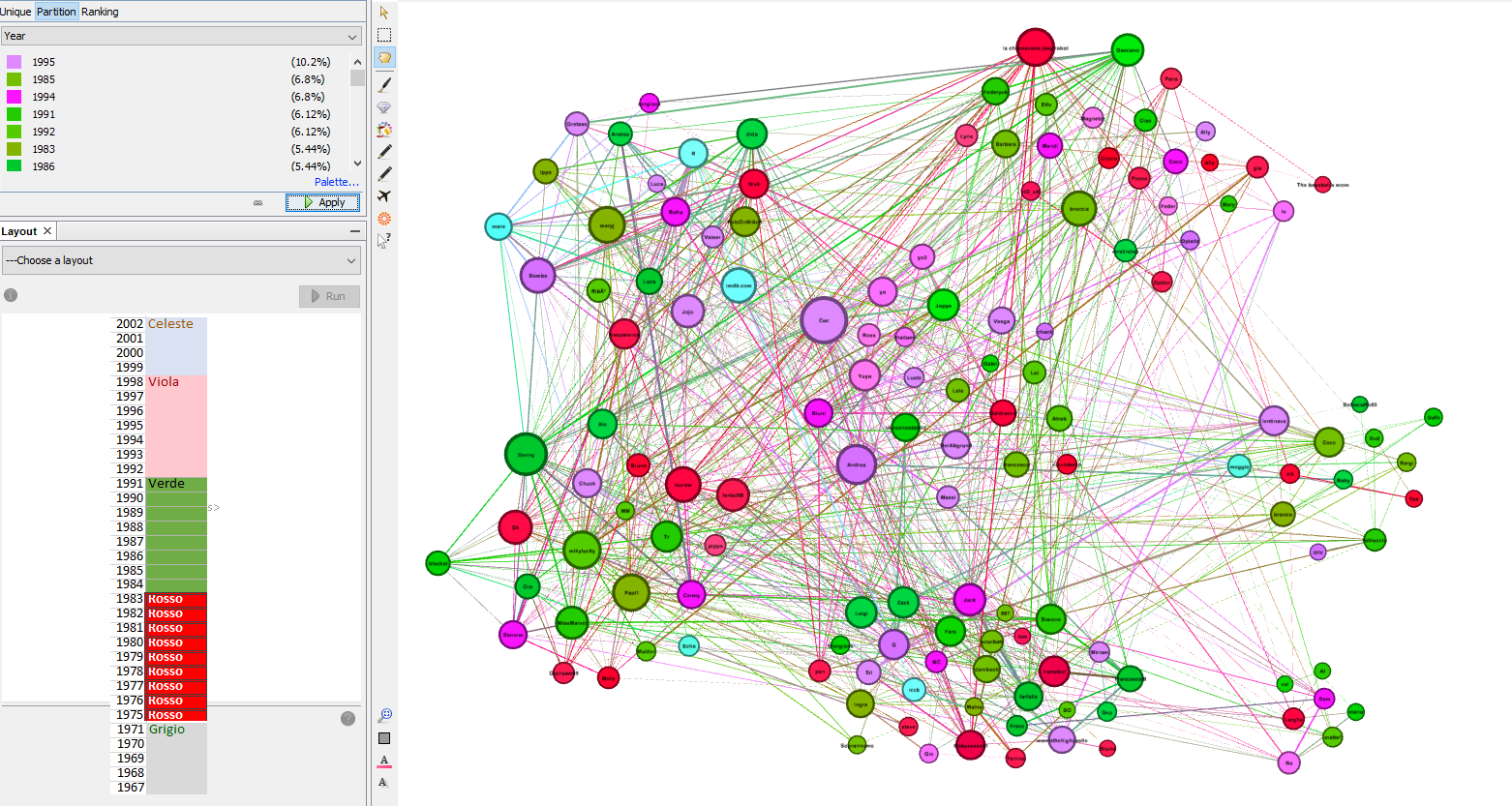
Anno di nascita
Un'altra informazione che gli utenti hanno inserito è l'anno di nascita. In questa immagine si vedono i nodi colorati per fascie di età ma mantenendo la topologia della rete divisa per regioni. Sempre dall'immagine si può notare che non esiste nessun collegamento tra l'età e la regione.
Genere preferito
L'ultima informazione che l'utente ha inserito è il genere cinematografico preferito. Come per l'anno di nascità, questa informazione non sembra essere un discriminante per la formazione della rete in quanto i colori sono distribuiti in maniera del tutto casuale.

Amicizia
Nell'ultima immagine, per curiosità, ho evidenziato di rosso i miei amici più cari ai quali avevo chiesto di effettuare il test. In questo caso sembrerebbe che l'amicizia reale traspaia anche nella rete sociale con il posizionamento dei nodi (rossi) in sole due regioni.

Nodi più rappresentativi
Una volta divisa la rete sociale in regioni, si cercano i nodi più rappresentativi. L'idea è di fare un algoritmo di predizioni quindi bisogna provare se effettivamente i nodi selezionati possono essere usati come un campione rappresentativo di una particolare regione. Se ciò fosse vero, si può evitare di fare eseguire n confronti (dove n è il numero di utenti) ma ne basterebbero m (dove m è il numero di regioni).
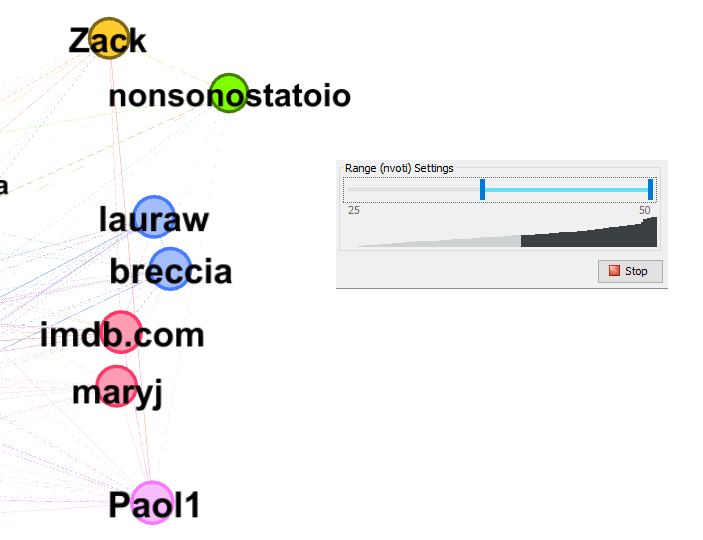
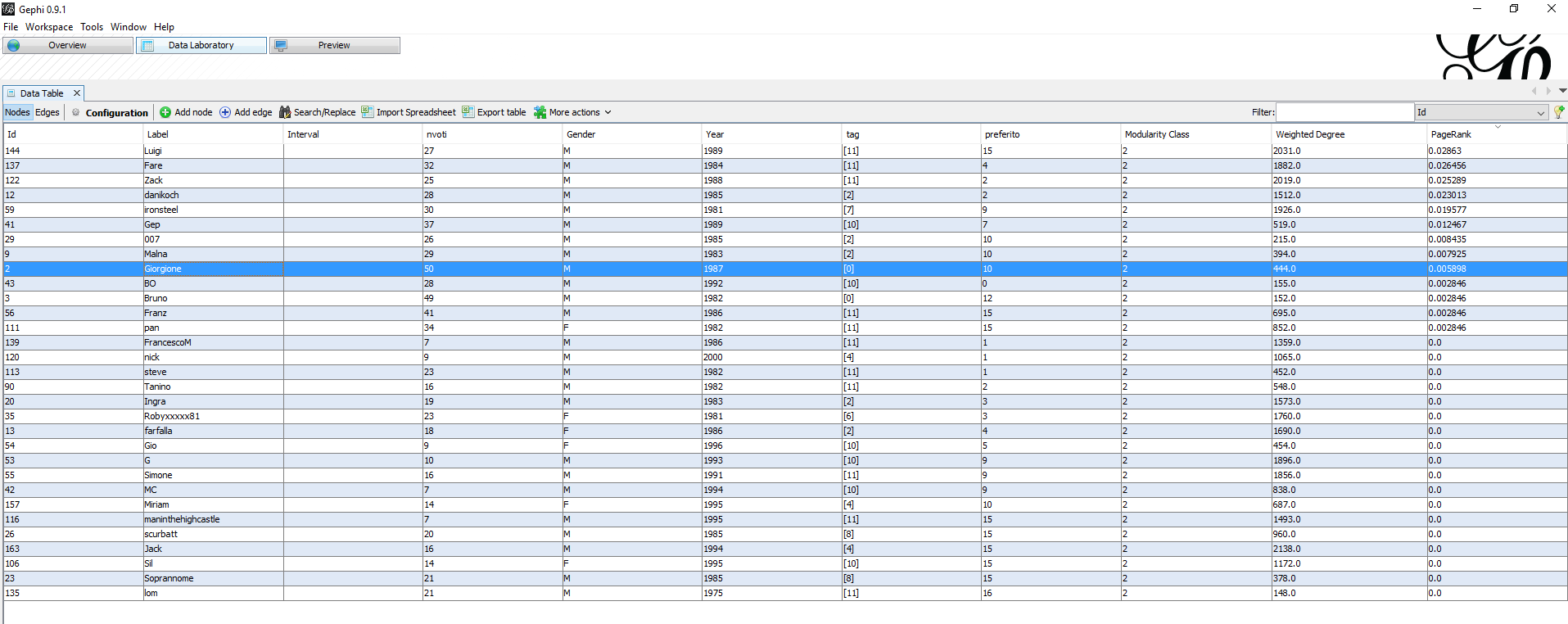
Per far questo, si isolano i due nodi di ogni regione che hanno il valore di deegree maggiore e almeno 25 voti espressi. Gephi mette a disposizione diversi filtri e quindi è bastato settare il range di nvoti>25 per avere nodi che potessero avere le caratteristiche desiderate.
Sono stati selezionati due nodi per regione per avere una maggiore quantità di dati. Questi nodi da ora in poi saranno chiamati 'superUser'.
Per vedere se effettivamente vi sono delle differenze tra le varie regioni, sono stati inseriti in excel i dati dei superUser. Il risultato è espresso il seguente grafico:
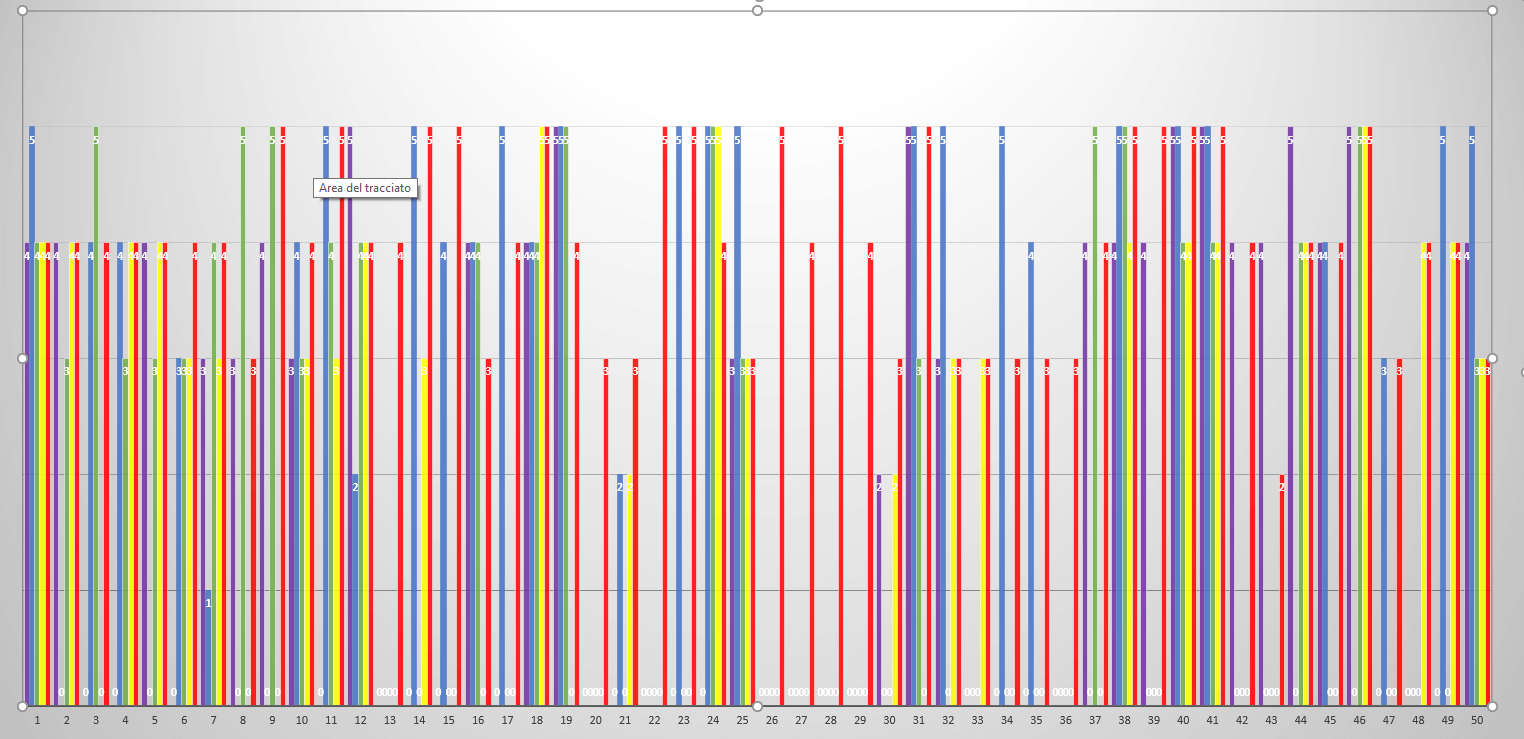
Purtroppo non ci sono grandi differenze tra di loro ma solamente su qualche film. Questa caratteristica però era abbastanza prevedibile.
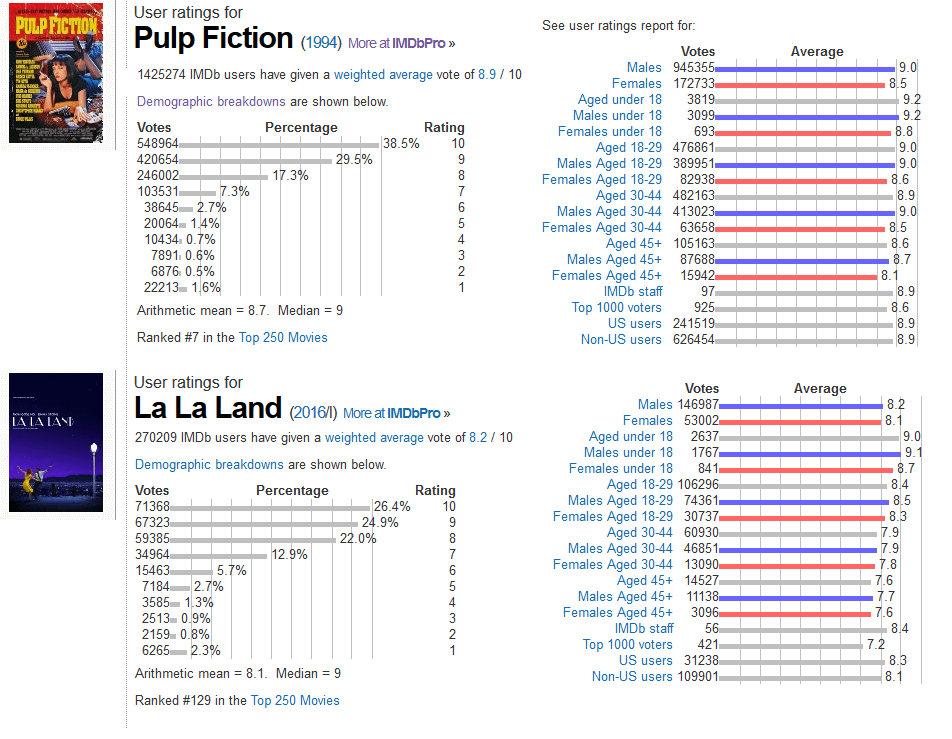
Come si può notare nella figura sottostante, anche in database enormi come Imdb.com i film classici (o anche l'ultimo vincitore dell'oscar 'miglior film') ricevevono voti estremanente posiviti che sfiorano l'80%.
I superUser per regione sono:
- Arancione > imdb.com (ID 172)
- Blu > lauraw (ID 36) > fertad69 (ID 161)
- Verde > Zac (ID 122) > danikoch(12)
- Azzurra > Bo (76) > matte1 (115)
- Marrone > Baby (22) > Cocc (10)
- Rossa > Francesco (ID1) > nonsonostatoio (ID 67)
- Gialla > la chiamavano jeeg robot(164) > rIO_sK(ID 61)
Una volta selezionati gli utenti più rappresentativi, si è sviluppato un algoritmo di predizione.
Algoritmo di predizione
Si è implementato un algoritmo di “Recommendation Systems” tramite “The Utility Matrix” (un esempio più complesso può essere trovato qui: http://infolab.stanford.edu/~ullman/mmds/ch9.pdf)
L’idea è semplice: avendo n superUser, si addestra l’algoritmo con 10 voti e si osserva quale superUser ha espresso il numero maggiore di voti uguali all'utente. Una volta che si è strovato trovato il superUser con gusti cinematrografici simili, si predice il voto dell’utente uguale a quello del superUser selezionato.
Se i superUser sono più di uno, si calcolano (pesando il voto con la percentuale di similarità con l'utente) i vari voti espressi per trovare il voto più probabile.
Dato che l’utente ha già votato, si confronta il voto predetto con il voto effettivo. Se il confronto è positivo si incrementa il contatore del successo, altrimenti niente.
Per confronto si incrementano i valori della "matrice dei confronti" dell’utente con i superUser. Se un utente dopo 20 votazioni, si ritrova più vicino ai gusti di un altro superuser, cambia la fonte di predizione.
Il codice di suggerimento da parte dei superUser con maggiore similarita è:
La media dei risultati di predizione per 145 nodi è stata del 35%. Il risultato non è proprio soddisfaciente
ma, tenendo conto che sono stati effettuati solamente 7 confronti, non è stato nemmeno così pessimo.
Aggiunta di un amico prossimo all'utente
Dato che
si è già analizzata la rete e si è trovato il "miglior amico" dell'utente, lo si aggiunge alla lista dei superUser.
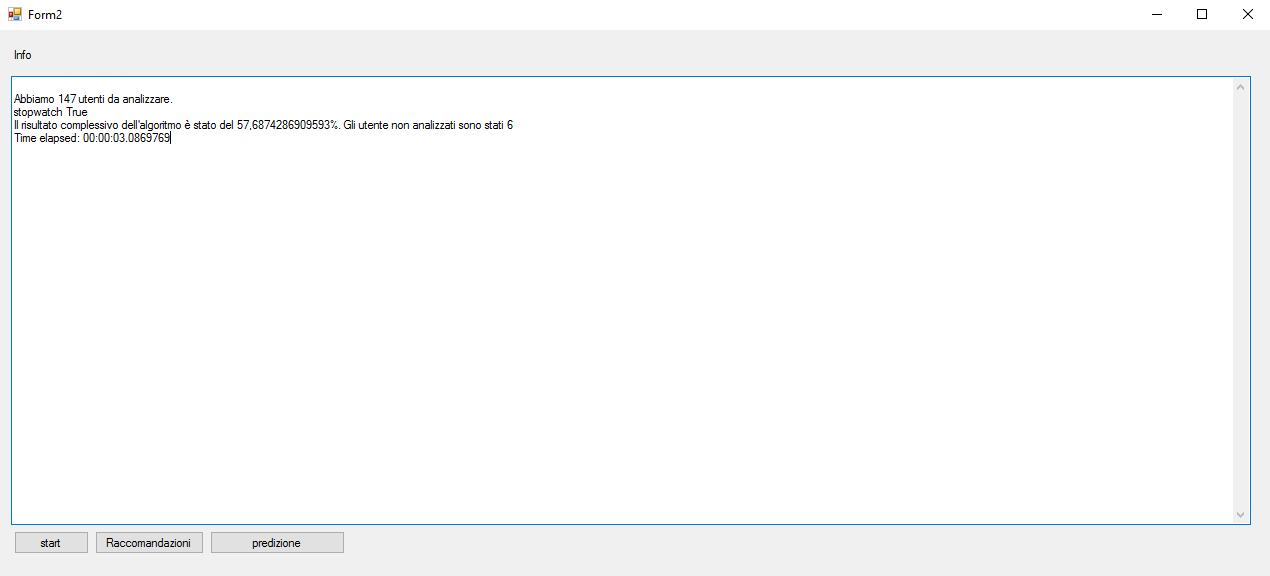
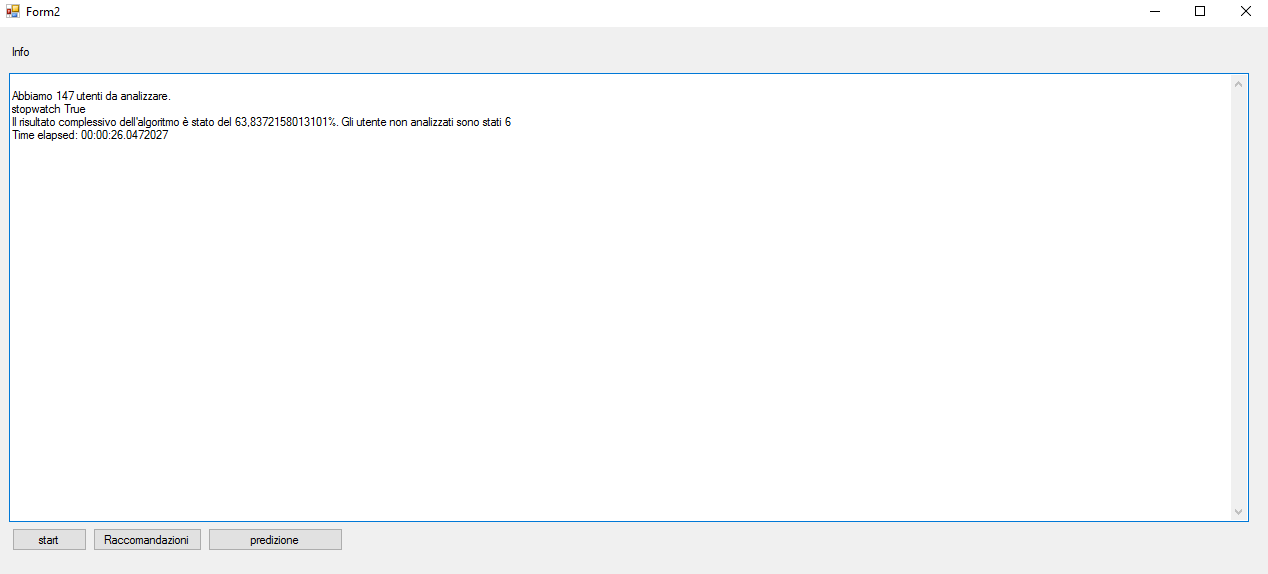
Eseguendo ancora una volta il programma di predizione, si ottiene:
Il risultato complessivo dell'algoritmo è stato del 45,9%. Gli utente non analizzati sono stati 6. Time elapsed: 00:00:04.1309774
Ovviamente, per trovare il miglior amico dell'utente, bisogna aver analizzato almeno una volta la rete sociale e quindi il numero di confronti necessari passa da 7 a n (dove n è il numero di utenti).
Questo esperimento dimostra che, aggiungendo alla lista dei superUser anche un solo utente che abbia un grado di similitudine molto alto, l'algoritmo reagisce in maniera positiva. L'aggiunta del 'miglior amico' però porta a dover analizzare ogni volta la rete e quindi può essere una soluzione più precisa a discapito di un tempo O(n).
Aggiunta di flessibilità
Il 35% di successi nella predizione nasce da una rigidità dell'algoritmo che riconosce come "risposta corretta" solo se i due utenti hanno esattamente espresso lo stesso voto, mentre per voti simili (es A vota 4 e B vota 5) pone la predizione come "sbagliata".
Se i voti sono simili e si aggiunge un po' di flessibilità attraverso l'incremento di mezzo punto, si ottiene:
Algoritmo senza l'aggiunta del giudizio 'best friend' 57%
Algoritmo con l'aggiunta del giudizio 'best friend' 64%
Cambio superUser
Cosa succederebbe se i superUser fossero presi da una singola regione invece che uno per ogni regione?
Con Gephi inizialmente si filtra per regioni, poi si ricalcola il pageRank e il weightdegree. Quindi i nodi più significativi si prendono una volta ordinati per pageRank e una volta ordinati per weightdegree.
Infine, trovati i nuovi nodi superUser, si inseriscono nell'algoritmo di predizione.
I risultati sono in questa tabella riepilogativa:
| |
|
Non flessibile |
Flessibile |
| Viola [23%] |
PageRank |
29,3 |
51,3
|
| Weight degree |
28,2 |
48,6
|
| Azzurra [17%] |
PageRank |
27,0 |
46,5
|
| Weight degree |
22,5 |
38,9
|
| Arancione [17%] |
PageRank |
30,1 |
50,1
|
| Weight degree |
31,6 |
51,7
|
| Best user per regione |
Weight degree |
35 |
57
|
Conclusioni
Come era prevedibile, si può vedere dalla tabella che l'algoritmo di predizione funziona meglio se prende i superUser uno in ogni regione piuttosto che tutti in una singola regione. Alcune considerazioni analizzando la tabella:
- La regione viola, la più popolosa [23%], riesce ad avvicinarsi ai risultati dell'algoritmo per regioni proprio in virtù
dell'alto numero di nodi presenti.
- La regione arancione, di cui fa parte l'utente Imdb, è la regione che rispecchia maggiormente la media dei film. Questa regione, anche se ha una percentuale di nodi del 17% sull'intera rete, riesce ad avere una alta media di predizione.
Alla fine si è sviluppato un semplice algoritmo di predizione che con la giusta flessibilità risulta abbastanza affidabile. Inoltre, si osserva che la corretta scelta dei nodi 'superUser' permette di dare maggiori percentuali di successo.
In conclusione, grazie a Gephi si riesce a determinare facilmente i migliori nodi da utilizzare.
Qui tutto il codice del progetto